AMD“特供版”遇阻,美国商务部的另一层焦虑:中美贸易摩擦再度升级
去年10月的美国商务部对华高性能芯片禁令,在2022年版的“传输带宽”和“总体处理性能”这两个指标上又做了迭代化的管制处理,取消了传输带宽限制,新增了性能密度指标,即要看芯片的总体处理性能除以裸片面积,以此作为计算方法作为评估出口许可证的基准。新规之下,英伟达对华特供版A800和H800也不再符合性能密度指标要求,连面向消费类的RTX4090显卡也不在豁免范围内。面对这个局面,有理由推断AMD的这款魔改版AI加速器在申请出口许可之前应该通过了企业内部合规部的审查,但却依然碰壁。
目前业界对此事的解读大多集中在两个层面,一是强调美国商务部BIS有“口径弹性”,是否给出口许可不完全按照纸面规定的门槛,一个是从应用场景上解读,强调美国对华AI芯片算力的遏制,卡人工智能大模型的升级。
诚然,这两个解读维度都有很强的说服力。但如果考虑到美国商务部半年多以来对华半导体技术路线调研的焦虑,尤其是华为Mate60的上市,代表了中国本土芯片工艺制程的重大突破,美方对此事的一系列反应,AMD的“MI309”暂时被禁背后或许还有另一个位面。
AMD MI300系列和英伟达H100的差异化
英伟达“阉割版”的H800被禁和AMD“阉割版”MI309被禁是不是完全算同一回事?是否可以用同一种思维框架去解读?对此我们不妨来看看二者在设计理念上的一个明显区别。
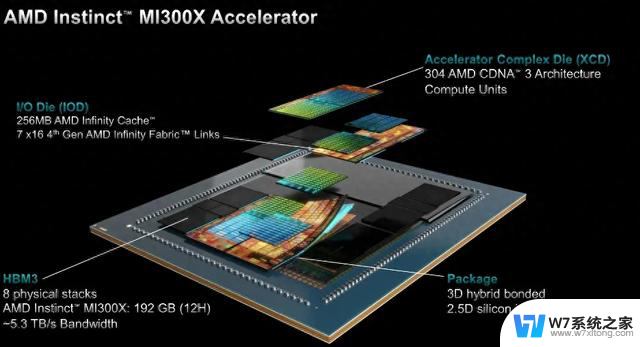
2023年12月,AMD发布最新MI300X GPU芯片,基于最新一代CDNA3计算架构,集成8个5nm工艺的XCD模块,同时还有四个6nm工艺的IOD模块和256MB无限缓存,将HBM 2.5D先进封装与 3D V-Cache技术结合,诞生了一个营销术语“3.5D”封装。可以说,MI300X一共有12个Chiplets,其中4个IODs在最底层,集成了8颗CDNA-3架构GPU(4 SoC die的Chiplets)与另外4个I/O die,如下图:
而英伟达则选择继续在单片硅上深耕GPU,H100没有采用Chiplet技术,背后的原因也并不复杂。在黄仁勋看来,die际之间的通讯带宽依然不能和传统Monolithic内部通信带宽相比,在高AI算力场合以及高端消费级显卡领域,英伟达为了保证传输的低延迟性,宁可承受高成本、相对较低良率的代价,也要坚持走大芯片GPU路线。
当然,Chiplet技术的采用深度关系到了die size即打破“光罩墙”与晶体管密度问题。AMD的MI300X仅采用5nm与6nm结合,就可以把die size做到超过1000平方毫米,并将晶体管密度堆到了超过1.5亿每平方毫米。除此之外,在更广阔的视角上,Chiplet技术导向着事关产业生态的重大革新。
Chiplet的初心,从美国军方谈起
2017年9月,美国国防部高级研究计划局(DARPA)官方网站上,突然出现了一则以“异构整合推动Chiplet发展”的新闻,吹皱了行业一池春水。DARPA表示,CMOS技术虽然实现了数字、模拟和混合信号模块的SoC集成,但也导致了和芯片设计、制造相关的成本的不断推高,而美国国防部的预算无法承受单片SoC成本带来的急剧上升,为了强化芯片设计系统的灵活性,并减少芯片迭代的设计时间,需要找到一个“IP复用”的新范例。
主持这项计划的项目经理丹·格林(Dan Green)当时表示,Chiplet可以将芯片设计与制造的思维方式、技能、技术优势和商业利益混合搭配。“如果计划成功,我们将获得更广泛的专用模块,我们将能够更轻松地以更低的成本集成到我们的系统中。这对于商业和国防部门来说应该是双赢。”
一言以蔽之,美国国防部的军用这一特殊应用场景,无法让其供货的供应商走“走量”模式,如何降低采购成本,是DARPA开启Chiplet项目的初心。最初加入该计划的主承包商包括了四家主要的半导体公司英特尔、美光科技,和两家EDA公司新思科技和Cadence,除此之外还有一些军用芯片承包商。抛开半导体产业这个圈子不谈,至少从美国军方看来,解决“摩尔定律”逐渐失效的问题,以及如何降低芯片设计成本,需要做到芯片性能与芯片工艺的解耦,Chiplet是代表了一种“省钱”的技术路线。
之后的几年,从芯片设计端到制造封装端的国际巨头,虽然切入到Chiplet技术的具体锚点各不相同,但参与其中的动机则契合了美国DARPA的想法。比如高带宽存储HBM是与GPU封装在一起,这主要由晶圆代工厂完成,台积电把2.5D封装中的中介层(interposer)当技术突破点,把不同工艺节点的die混封,加快新工艺芯片的上市时间,无论英伟达的2.5D还是AMD的3.5D,都让台积电收益巨大。
从作为买方市场的DARPA入手看Chiplet当初被推广的理念,我们发现它指引了一种产业生态演化的理想状态,即在一个无限广阔,完全自由开放的Chiplet市场上,客户就像厨子在菜市场采购食材一样,自由mix-and-match,IP可以复用,不同工艺节点混搭,研发成本分摊,也可以带动IP和EDA赛道的创新。
AMD与Chiplet
回到AMD对华定制化AI加速器被阻的这件事本身,我们有理由推断,AMD在Chiplet之路上走的“过快”,反而引发了美国出口管制政策制定者的忌惮。因为,相比英伟达和英特尔,AMD真正引领了Chiplet商用落地的成熟和生态建设,并且在有限范围里部分实现了DARPA的那种自由开放的样态。
AMD的EPYC处理器经过了代号为那不勒斯、罗马、米兰和热那亚等多次迭代,有效形成了CCD Die和I/O Die分割演进的打法,为了减少成本也采用了不同代工厂的分散布局,把相对工艺不那么高的I/O Die扔给格芯,而需要先进工艺的CPU和3D V-Cache让台积电代工,其他产品线如Ryzen系列也可以复用CCD模块,降低了研发费用。

AMD CEO Lisa Su 曾表示:Chiplet可以作为一个平台,让第三方IP导入更容易
不过,目前Chiplet距离理想中的蓝海还有很长的路要走,这是业界多年来长期讨论的焦点。如die to die的互联标准问题,Chiplet先进封装带来的供电和散热问题,以及DTCO理念(协同设计)理念所要求的联合设计、验证和测试难题,考验着EDA工具的适配度。
Chiplet,一片混沌的蓝海
从产业上下游生态整合的角度来看,可以参考中兴微高速互连总工程师吴枫的一段分析。他在去年芯和半导体用户大会上发表了以“算力时代的Chiplet技术和生态发展展望”为主题的演讲。在演讲中,他表示Chiplet技术和生态发展对先进封装的促进,出现了一个“高门槛但低保护”的问题。他指出,对所有的设计公司而言,先进封装属于外购的技术,即便它的技术门槛特别高,竞争对手同样也可以购买通用性服务,没有什么专利壁垒,这对于新进赛道的公司是一个好消息,但是Chiplet 的这种模块化设计,其实拆分了半导体公司的方案,无限开放的Chiplet蓝海其实增加了芯片设计公司的差异化竞争难度。
总而言之,目前Chiplet从接口IP的导入以及设计和封装的很多环节,还处在被市场待为“催熟”的混沌时代,一个标准化的多元采购体系也尚待建立。就在昨天,全球知名半导体技术分析平台“Semiengineering”以Chiplet IP Standards Are Just The Beginning”(Chiplet IP标准才刚刚起步)为题,采访了Arteris 解决方案和业务开发副总裁 Frank Schirrmeister、Cadence硅解决方案部产品营销总监Mayank Bhatnagar、Expedera营销副总裁Paul Karazuba等业界大佬,他们纷纷表示,直到今天,Chiplet还没有哪一家真正做到“异构集成”,玩家或多或少以同质集成,或者是完全垂直集成类型的环境中完成了Chiplet的代工和封装。
对中国Chiplet玩家来讲,混沌即阶梯
根据知识产权管理技术公司Anaqua的Acclaim IP数据库的分析,近年来中国半导体公司的Chiplet相关专利申请急剧上升,Anaqua分析解决方案总监Shayne Phillips 表示,华为2022年在中国发布了900多项与Chiplet相关的专利申请和授权,而2017年为30项。这引起了美国相关部门的警觉。

华为有关芯片堆叠封装结构及其封装方法的专利申请(图源:国家知识产权局)
以CSIS为代表的美国智库早已发布多篇报告,惊呼中国虽然在用于AI推理和训练的单片集成的大型GPU方面,和美国的差距依然很大,但完全可以通过Chiplet技术技术与市场双向牵引实现赶超。
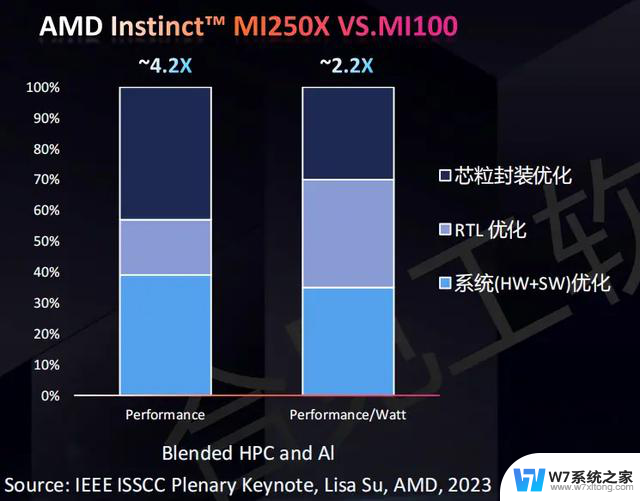
AMDMI250X和MI100相比,在没有制程工艺提升的情况下,依靠Chiplet封装优化,RTL、IP的验证优化,就能取得4.2倍的性能提升和2.2倍的能效提升(图片来源:合见工软)
从现实层面上看,华为Mate60的突破,更增加了美国商务部对华芯片制程遏制的焦虑感。因此,AMD“MI309”被禁的深层次原因,也许不是芯片本身的性能密度,而在于它代表了一种技术路线的未来导向性。
【来源:集微网】